
Masculinity Survey
- Alex Ricciardi

- Feb 18, 2021
- 12 min read
Updated: Feb 20, 2021
My Codecademy Masculinity Survey Project from the Data Scientist Path Foundations of Machine Learning: Unsupervised Learning.
+ Project Goal
Find patterns in the way men view masculinity by utilizing the K-Means algorithm on a FiveThirtyEight masculinity survey data.
+ Overview
In this project, I investigated the way people think about masculinity by applying the K-Means algorithm to data from FiveThirtyEight. FiveThirtyEight is a popular website known for their use of statistical analysis in many of their stories.
FiveThirtyEight and WNYC studios used 'masculinity-survey.pdf' to get their male readers' thoughts on masculinity. FiveThirtyEight's article What Do Men Think It Means To Be A Man? contains their major takeaways.
+ Project Requirements
Be familiar with:
Python3
Machine Learning: Unsupervised Learning
The Python Libraries:
Pandas
NumPy
Matplotlib
Sklearn
+ Links
▪ Investigating the Data
The provided data, 'masculinity.csv', contains the FiveThirtyEight survey responses' results from the FiveThirtyEight masculinity survey questions, 'masculinity-survey.pdf'.
+ The questions
After investigating 'masculinity-survey.pdf', I categorized the questions in it as followed:
Open-end questions
Open-ended questions are free-form survey questions that allow respondents to answer in open text format so that they can answer based on their complete knowledge, feeling, and understanding. It means that the response to this question is not limited to a set of options.
The questions 3, 6, 16, 23 and 27 are open-ended questions.
Note: the investigating results of the masculinity.csv data showed that the data representing the questions above was not provided.
Masculinity multiple choice questions
Multiple Choice Questions form the foundation of any survey or questionnaire as they provide a set of answer options for the respondents to select from. They are the perfect means to understand respondent preferences and produce impactful results. Not only do they bring balance to a survey but they also make it easier and quicker for the respondents to answer the survey.
The following questions, are multiple choice questions:
1 to 2 and 4 to 5 (Ideas about masculinity).
8 to 9 (Lifestyle).
10 through 15 (Employment).
17 through 22 (Relationships).
24 through 30, and 34 through 36 (Demographics).
Note: the questions 34 through 36 are not part of the survey pdf file, but the questions data is found in the data csv file. The questions 31 through 33 are missing from both files.
Multiple choice questions matrix 'Question 7' is a matrix of multiple choice sub-questions, the matrix is particularly interesting for this project. The sub-questions 7 and 1 through 4 are traditionally seen as feminine activities and the sub-questions 5, 6, 8 and 9 are traditionally seen as masculine activities. The matrix sub-questions' responses can be utilized by the K-Means algorithm to find out if 2 clusters based on those responses represent traditionally feminine and traditionally masculine people.
- Questions list
From the information found in 'masculinity-survey.pdf', I created a survey question Series.
The python file 'survey_questions.py' creates the Series.

+ The response data
The response data is found in the provided 'masculinity.csv' file.
I loaded the data into a DataFrame named 'survey'. This file contains the raw response data from the masculinity survey.
I answered the following questions using the Pandas library functionality:
What are the names of the columns?
How many rows are there?
'How many people said they often ask a friend for professional advice?' This is the first sub-question of the question 7.
And more.
Survey DataFrame sample:

- Column names






The 'survey' DataFrame has 98 columns and 1188 surveys, the column are questions' responses and survey responders collected information.
- Checking for duplicated columns
'race2' and 'racethn4'
# race2
White 1015
Non-white 174
Name: race2, dtype: int64
# racethn4
White 1014
Other 92
Black 41
Hispanic 41 W
1 Name: racethn4, dtype: int64The columns 'race2' and 'racethn4' are not duplicated columns.
The column 'race2' classifies survey responders as 'White' or 'Non_white'.
The column 'racethn4' classifies survey responders as 'Black', 'White', 'Hispanic', 'Other'
and 1 'W'.
'educ3' and 'educ4'
'educ3'[0]
College or more
'educ4'[0]
Post graduate degree
'educ3'[3]
College or more
'educ4'[3]
Post graduate degree
'educ3'[10]
College or more
'educ4'[10]
Post graduate degreeSome of the values 'College or more' from the column 'educ3' have been replaced
by the value 'Post graduate degree' in the column 'educ4'. Even if the columns 'educ3'
and 'educ4' are not exact duplicates of each other, I decided to drop the column 'educ3'
from the 'survey' DataFrame, and rename the the column 'educ4', 'education'.
Survey column names:
Index(['StartDate', 'EndDate', 'q0001', 'q0002', 'q0004_0001',
'q0004_0002', 'q0004_0003', 'q0004_0004', 'q0004_0005',
'q0004_0006', 'q0005', 'q0007_0001', 'q0007_0002', 'q0007_0003',
'q0007_0004', 'q0007_0005', 'q0007_0006', 'q0007_0007',
'q0007_0008', 'q0007_0009', 'q0007_0010', 'q0007_0011',
'q0008_0001', 'q0008_0002', 'q0008_0003', 'q0008_0004',
'q0008_0005', 'q0008_0006', 'q0008_0007', 'q0008_0008',
'q0008_0009', 'q0008_0010', 'q0008_0011', 'q0008_0012', 'q0009',
'q0010_0001', 'q0010_0002', 'q0010_0003', 'q0010_0004',
'q0010_0005', 'q0010_0006', 'q0010_0007', 'q0010_0008',
'q0011_0001', 'q0011_0002', 'q0011_0003', 'q0011_0004',
'q0011_0005', 'q0012_0001', 'q0012_0002', 'q0012_0003',
'q0012_0004', 'q0012_0005', 'q0012_0006', 'q0012_0007', 'q0013',
'q0014', 'q0015', 'q0017', 'q0018', 'q0019_0001', 'q0019_0002',
'q0019_0003', 'q0019_0004', 'q0019_0005', 'q0019_0006',
'q0019_0007', 'q0020_0001', 'q0020_0002', 'q0020_0003',
'q0020_0004', 'q0020_0005', 'q0020_0006', 'q0021_0001',
'q0021_0002', 'q0021_0003', 'q0021_0004', 'q0022', 'q0024',
'q0025_0001', 'q0025_0002', 'q0025_0003', 'q0026', 'q0028',
'q0029', 'q0030', 'q0034', 'q0035', 'q0036', 'race2',
'racethn4', 'education', 'age3', 'kids', 'orientation',
'weight'],
dtype='object')- Number of people who said that they 'often ask a friend for professional advice':
First sub-question of the question 7.


- The questions 34 through 36 are not described in the 'masculinity-survey.pdf'.
I investigated the response data to find out the questions' topics.
Question: q0034
$50,000-$74,999 197
$75,000-$99,999 174
$25,000-$49,999 163
Prefer not to answer 162
$100,000-$124,999 131
$200,000+ 95
$10,000-$24,999 71
$125,000-$149,999 66
$150,000-$174,999 49
$0-$9,999 49
$175,000-$199,999 30
Name: q0034, dtype: int64
Question: q0035
Pacific 224
South Atlantic 218
Middle Atlantic 172
East North Central 151
West South Central 113
Mountain 111
West North Central 83
New England 62
East South Central 43
Name: q0035, dtype: int64
Question: q0036
Windows Desktop / Laptop 664
iOS Phone / Tablet 223
Android Phone / Tablet 157
MacOS Desktop / Laptop 121
Other 22
Name: q0036, dtype: int64From the response data I deducted:
The question-34 topic is about the survey responder income.
The question-35 topic is about the survey responder time zone.
The question-36 topic is about device used by the responder to take the survey.
▪ Mapping the Data
In order to use the K-Means algorithm with this data, I needed to first figure out how to turn the response data into numerical data. For this exercise, I chose to use the response data from 'question 7', the question is a matrix of multiple choice sub-questions. The sub-questions 7 and 1 through 4 are traditionally seen as feminine activities and the questions 5, 6, 8 and 9 are traditionally seen as masculine activities. The matrix sub-questions' responses can be utilized by the K-Means algorithm to find out if 2 clusters based on those responses represent traditionally feminine and traditionally masculine people. I could cluster the data using the phrases 'Often' or 'Rarely', but I needed to turn the phrases into numbers, I decided to map the data in the following way:
"Often" -> 4
"Sometimes" -> 3
"Rarely" -> 2
"Never, but open to it" -> 1
"Never, and not open to it" -> 0.
Note, it's important that these responses are somewhat linear. 'Often' is at one end of the spectrum with 'Never, and not open to it' at the other. The other values fall in sequence between the two. I could perform a similar mapping for the 'education' responses , but there isn't an obvious linear progression in the 'racethn4' responses.
Count of the mapped question 7 first sub-question:

▪ Plotting Question 7 Response Data
The 'question 7' has 11 different features, sub-questions, I could plug in the sub-questions' response data into a K-Means algorithm, but first I wanted to explore the sub-questions' responses further, I visualized the features into a grid of 2D scatter plots,
Question 7 sub-questions list:
'Ask a friend for professional advice' 'Ask a friend for personal advice' 'Express physical affection to male friends, like hugging, rubbing shoulders' 'Cry' 'Get in a physical fight with another person' 'Have sexual relations with women, including anything from kissing to sex' 'Have sexual relations with men, including anything from kissing to sex' 'Watch sports of any kind' 'Work out' 'See a therapist' 'Feel lonely or isolated'
Question 7 scatter plots:

+ Analyzing question 7 scatter plots
The grid has 55 features combinations, 55 scatter plots.
In this section I looked at some interesting features combinations including the responses data from the question 'q0007_0001' , 'Ask a friend for professional advice'.
'q000_0001' vs 'q000_0002'B 'Ask a friend for professional advice' vs 'Ask a friend for personal advice'. The scatter plots show, if the responder is less likely to ask a friend for professional advice, he is also less likely to ask a friend for personal advice. On the other hand, if the responder is more likely to ask a friend for professional advice, he is also more likely to ask a friend for personal advice.
'q000_0001' vs 'q000_0003' 'Ask a friend for professional advice' vs 'Express physical affection to male friends, like hugging, rubbing shoulders'. The scatter plots show, if the responder is less likely to ask a friend for professional advice, he is also less likely to express physical affection to male friends. On the other hand, if the responder is more likely to ask a friend for professional advice, he is also more likely to express physical affection to male friends.
'q000_0001' vs 'q000_0004' 'Ask a friend for professional advice' vs 'Cry'. The scatter plots show, when compared to all other responses, if the responder answer to the question 'Ask a friend for professional advice' is 'Never, and not open to it', the responder is less likely to cry or to admit that he cries.
'q000_0001' vs 'q000_0007' 'Ask a friend for professional advice' vs 'Have sexual relations with men, including anything from kissing to sex'. The scatter plots show, when compared to all other responses, if the responder answer to the question 'Ask a friend for professional advice' is 'Sometimes', the responder is more likely to be open to have sexual relations with men.
'q000_0001' vs 'q000_0010' 'Ask a friend for professional advice' vs 'See a therapist'. The scatter plots show, if the responder is less likely to ask a friend for professional advice, he is also is less likely to see a therapist. On the other hand, if the responder is more likely to ask a friend for professional advice, he is also more likely to to see a therapist.
'q000_0001' vs 'q000_0011' 'Ask a friend for professional advice' vs ''Feel lonely or isolated'. The scatter plots show, when compared to all other responses, if the responder answer to the question 'Ask a friend for professional advice' is 'Never, and not open to it', the responder is less likely to not feel lonely or isolated or to admit that he feels lonely or isolated.
▪ K-Means Model
K-Means clustering is one of the simplest and popular unsupervised machine learning algorithms. Understanding K-means Clustering in Machine Learning
The objective of K-Means is simple: group similar data points together and discover underlying patterns. To achieve this objective, K-means looks for a fixed number (k) of clusters in a dataset. AndreyBu
For this exercise, I used sklearn.cluster.KMeans K-Means algorithm from the SKlearn python library, and the response data from 'question 7', like I described earlier, the question is a matrix of multiple choice sub-questions.
The sub-questions 7 and 1 through 4 are traditionally seen as feminine activities and the sub-questions 5, 6, 8 and 9 are traditionally seen as masculine activities.
I used the K-Means algorithm to explore the sub-questions' responses and find out if 2 clusters based on those responses represent traditionally feminine and traditionally masculine people.
+ Training model with selected question 7 sub-question responses
# Isolates selected sub-questions and drops NaN values columns
# Finds question 7 sub-questions names
pattern = re.compile('q0007')
q0007_id = [col_name for col_name in survey.columns if pattern.match(col_name)]
q0007_responses = q0007_responses.dropna(subset = q0007_id)
# Initializes K-Means model,
# the argument "random_state = 1 " sets the random seed to 1, to ensure # that results are reproducible
classifier = KMeans(n_clusters = 2, random_state=1)
classifier = KMeans(n_clusters = 2, random_state=1)
# Training/Classifying selected sub-question responses
classifier.fit(q0007_responses[q0007_id])- Centroids:
K-Means is a centroid-based algorithm, or a distance-based algorithm, where we calculate the distances to assign a point to a cluster. In K-Means, each cluster is associated with a centroid.
# Stores centroids coordinates
centroids_q0007 = pd.DataFrame(classifier.cluster_centers_)
# Display
pd.set_option('precision', 8)
centroids_q0007.style.hide_index()

Note: The inputted data has 11 features and 2 clusters, 'cluster_centers' returns 2 centroids in 11-dimensions (1 dimension per sub-question). Each list corresponds to the coordinates of the centroids in R^11.

▪ Separating by clusters
Like I described earlier, when we look at the 'question 7' sub-questions, the sub-questions 7 and 1 through 4 are traditionally seen as feminine activities and the sub-questions 5, 6, 8 and 9 are traditionally seen as masculine activities.
The cluster-1 centroid has higher value for the sub-questions 7 and 1 through 4 than the cluster-2 centroid.
On the other hand, the cluster-2 centroid has higher value for the sub-questions 5, 8 and 9 than the cluster-1 centroid.
I was able to find out more information about the clusters by looking at the specific members of each cluster. 'classifier.labels_' shows which cluster every row in the DataFrame corresponds to.
For example, if 'classifier.labels_' was [1, 0 ,1], then the first row in the DataFrame would be in cluster one, the second row would be in cluster 0, and the third row would be in cluster one. A row represents one persons responses to every question in the survey.
[in]
classifier.labels_
[out]
array([0, 0, 1, ..., 0, 1, 1])+ Adding classifications results to the mapped question 7 DataFrame
Question 7 DataFrame

+ Separating question 7 response data by clusters
Question 7 cluster-1 DataFrame:

+ Plotting Question 7 Clusters
I decided to visualize the 'question 7' sub-questions response data into 2 separated scatter plots graphs, one representing the data from cluster-1 and the other one representing cluster-2.

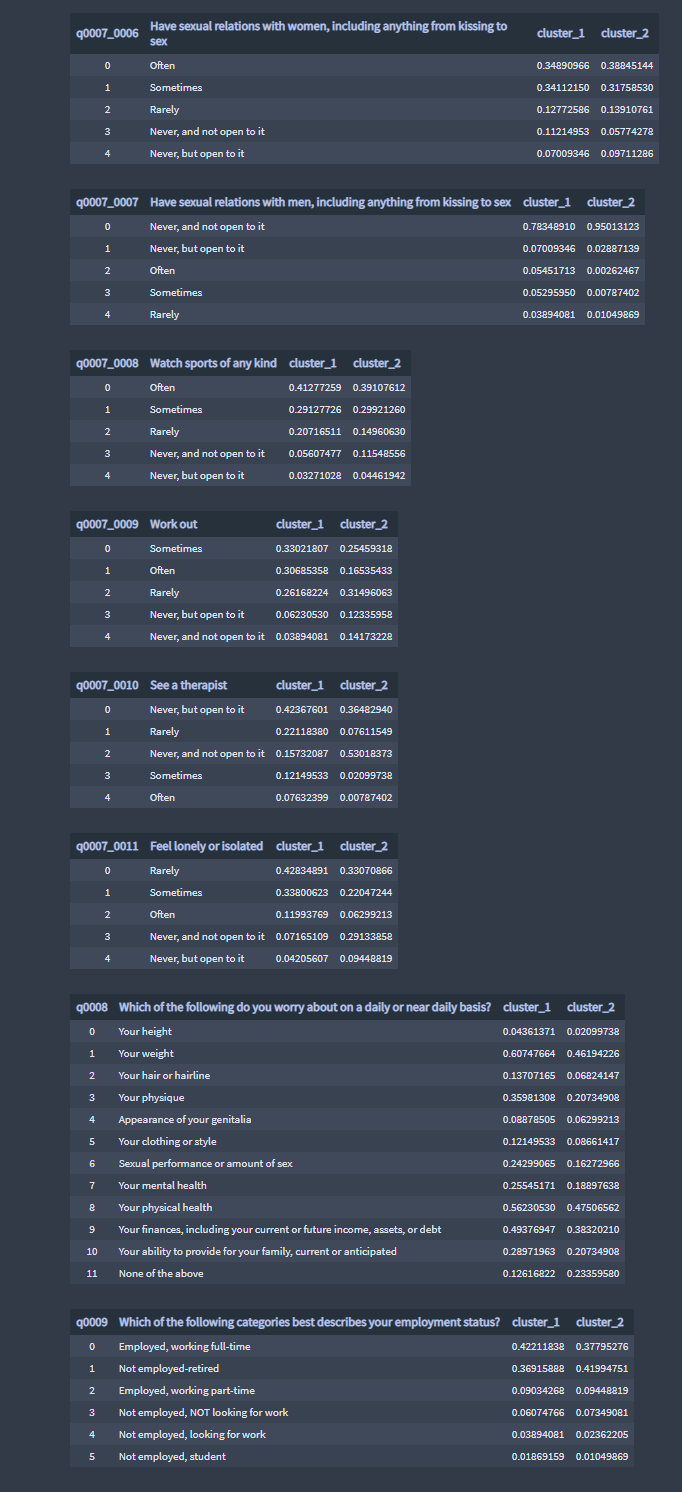
Cluster-1 The scatter plots show, for the sub-questions 1 through 4, that the cluster has a very low amount of 'Never, and not open to it' responses, the responses amount gets progressively greater from 'Sometimes' to 'Often'. The sub-questions 1 through 4 are traditionally seen as feminine activities, the cluster seems to represent a group of people expressing behaviors which are traditionally seen as feminine activities.
Cluster-2 The scatter plots show, for the sub-questions 7 and 1 through 4, that the cluster has a very low amount of 'Often' responses, and the responses amount gets progressively greater from 'Sometimes' to 'Never, and not open to it'. The sub-questions 7 and 1 through 4 are traditionally seen as feminine activities, the cluster seems to represent a group of people expressing behaviors which are not traditionally seen as feminine activities, but they are expressing activities traditionally seen as masculine activities, questions 6, 8 and 9.
In the cluster-1, the sub-questions 6 and 7 responses data are very similar and equally distributed. In the cluster-2, the sub-questions 6 and 7 responses data are not similar, sub-question 7 as a significantly greater amount of 'Never, and not open to it' responses than all other sub-question 7 responses. Sub-question 6, 'Have sexual relations with women, including anything from kissing to sex', is traditionally seen as masculine activities. On the other hand, sub-question 7, 'Have sexual relations with men, including anything from kissing to sex', is traditionally seen as feminine activities. When comparing both scatter plots graphs, sub-questions 6 and 7 response data, the men from cluster-1 seem more likely to express bi-sexual and homosexual activities than men from cluster-2. From the above findings, I classified the clusters as followed:
Cluster-1, people expressing behaviors which are traditionally seen as feminine activities
Cluster-2, people expressing behaviors which are traditionally seen as masculine activities
+ Separating the survey data by Clusters
Using the cluster results from 'question 7' responses, I separated the entire 'survey' data by clusters.
- Modifying the survey_questions Series:
Some of the features from the 'survey' DataFrame, like 'kids', are not found in the 'survey_questions' Series, I added a list of the those features to the 'survey_questions' Series.
Note, except for 'weight', the missing features are the response results from some of the questions of the provided 'masculinity-survey.pdf file'.
For example: the feature 'kids' contains the response results of question 4, 'Do you have any children?'.
'q0025' is the question 25 responses reference in the 'survey' DataFrame.
I created a survey questions DataFrame, survey_questions_df.

- Clusters DataFrames:
I separated the 'survey' data in two DataFrames, one containing the survey responses relative to cluster-1 and the other one to cluster-2.
Sample from the 'cluster_1_df' DataFrame:

▪ Investigating the Clusters Members
I investigated the survey's features:
by looking at the following questions responses percentages,
q0004, where have you gotten your ideas about what it means to be a good man?
q0010, in which of the following ways would you say it’s an *advantage to be a man at your work right now?*
q0011, in which of the following ways would you say it’s a *disadvantage to be a man at your work right now?*
by answering the following question,
which demographic features have stronger correlations with ideas of masculinity (sexual orientation, age, race, marital status, parenthood?)
Note, earlier I classified the clusters as followed:
Cluster-1, people expressing behaviors which are traditionally seen as feminine activities
Cluster-2, people expressing behaviors which are traditionally seen as masculine activities
+ The investigate_member() function
The function takes the argument 'member', it is a question id number, from the 'survey_question['q_id']' Dataframe.
The function returns the percentages of responses for the inputted question, per selectable responses, and by cluster.
Takes the arguments:
member, a string data type
cluster_1, a DataFrame data type defaulted to cluster_1_df
cluster_2, a DataFrame data type defaulted to cluster_2_df
survey, a DataFrame data type defaulted to survey
Computes the member percentages of responses, per selectable responses, and by cluster
Returns a DataFrame of the percentages of responses, per selectable responses, and by cluster

+ Responses investigation results

The people from cluster-1, seem to get their ideas about what it means to be a good man more from other than people from cluster-2.

The people from cluster-1 expressed more than people from cluster-2, that bean a man in their workplace has financial and leadership advantages.

The people from cluster-1 expressed more than the people from cluster-2 that men in their workplace are more likely to have their position at work frightened by management wanting to hire and promote women, and men are more likely at risk to be accused of sexual harassment, being sexist or racist
+ Answering the demographic question
In the 'survey_questions_df', the demographic features are found from the indexes 29, 'q0024', to 44, 'weight'.

Some of the demographic features are closely related like 'q0025', 'Do you have any children?, and 'kid', 'Children'.
For this exercise, I decided not to use some of related features.

- Demographic features correlation with the traditional ideas of masculinity, Cluster-2
In this section, I analyzed the demographic features correlation with traditional ideas of masculinity by isolating the cluster-2 higher than cluster-1 features investigation results, and by calculating the difference between the two.

The demographic features having the strongest correlations with the ideas of traditional masculinity are:
straight men over 65 years old that use windows desktops or/and laptops as personal computers, and have children over 18 years old.
- Demographic features correlation with the non-traditional ideas of masculinity, Cluster-1
In this section, I analyzed the demographic features correlation with non-traditional ideas of masculinity by isolating the cluster-1 higher than cluster-2 features investigation results, and by calculating the difference between the two.

The demographic features having the strongest correlations with the ideas of non-traditional masculinity are:
Gay or bisexual post graduate degree men between 35-64 years old that use iOS phones or/and tablets.
+ All the features investigation results
The following data tables are all the features investigation results, if you are interested to take a look at it.








Comments