
OkCupid
- Alex Ricciardi

- Apr 9, 2021
- 10 min read
Updated: Apr 10, 2021
My Codecademy OkCupid Machine Learning Portfolio Project from the Data Scientist Path. I divided the project in two sections:
OKCupid ID - Data Investigation
Provided data investigation
NLP text pre-processing
OkCupid TF-IDF - NLP Term Frequency–Inverse Document Frequency (TF-IDF)
TF-IDF scores computation
TF-IDF terms results analysis
+ Project Goal
Using data from OKCupid, an app that focuses on using multiple choice and short answers to match users, formulate questions and implement machine learning techniques to answer those questions.
+ Overview
In recent years, there has been a massive rise in the usage of dating apps to find love. Many of these apps use sophisticated data science techniques to recommend possible matches to users and to optimize the user experience. These apps give us access to a wealth of information that we’ve never had before about how different people experience romance.
In this portfolio project, I analyze data from OKCupid, formulate questions and implement machine learning techniques to answer the questions.
+ Project Requirements
Be familiar with:
Python3
Machine Learning:
Unsupervised Learning
Supervised Learning
Natural Language Processing
The Python Libraries:
re
gc
Pandas
NumPy
Matplotlib
Collections
Sklearn
NLT
+ OkCupid DI project memory management
This project requires jupyter notebook to use the python 64bit version, the 32bit version will generate a MemoryError when manipulating the provided data. If you want to use this project code lines and you are unsure of which python bit version your Jupyter Notebook uses, you can enter the following code lines in your notebook:
import struct
print(struct.calcsize("P") * 8)You may also consider, increasing your Jupyter Notebook defaulted maximum memory buffer value.
The Jupyter Notebook maximum memory buffer is defaulted to 536,870,912 bytes.
How to increase Jupyter notebook Memory limit?
Configure (Jupyter notebook) file and command line options
I increased my Jupyter Notebook maximum memory buffer value to 8GB, my PC has 16GB of RAM. When using the full size of the provided data, you need a minimum of 3GB of free RAM to run this project. If RAM is an issue, you may consider using a sample of the provided data instead of the entire size of the provided data. You can also utilize:
Garbage Collector interface library, Python Garbage Collection: What It Is and How It Works
And the del python function, What does “del” do exactly?
+ Links
OkCupid DI code (Jupyter Notebook)
OkCupid TF-IDF code (Jupyter Notebook)
OkCupid DI
Data Investigation
In this section:
I investigate the OkCupid provided data
After investigating the data:
I formulate questions
And I pre-process the data
▪ Investigating the Data
Before formulating questions, I need to get familiar with the data, in this section I inspect the provided data and learn from it
+ Loading provided data
The data was provided in the Comma-Separated Value format, 'profiles.csv'.
The provided data contains 59'946 profiles and 31 profile features.
+ Features
To inspect the feature names and data types, I use the function 'column_types()' from my imported file 'project_library.py'.
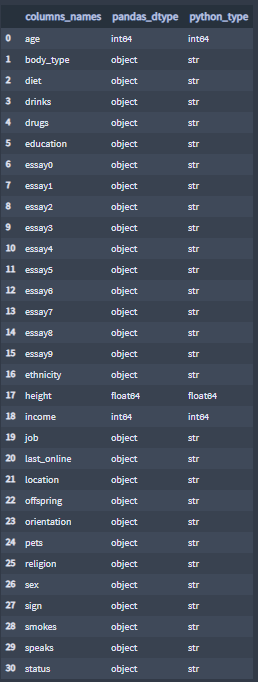
The provided data does not contain dictionary, dates, tuples or lists data types. The provided contains the basic data types, strings, integers and floats.
The feature descriptions can be found in okcupid_codebook.txt, provided by Albert Y. Kim.
+ Feature Essays
Essays are responses to the following questions:
'essay0' - My self summary
'essay1' - What I’m doing with my life
'essay2' - I’m really good at
'essay3' - The first thing people usually notice about me
'essay4' - Favorite books, movies, show, music, and food
'essay5' - The six things I could never do without
'essay6' - I spend a lot of time thinking about
'essay7' - On a typical Friday night I am
'essay8' - The most private thing I am willing to admit
'essay9' - You should message me if...
Note: All essay questions are fill-in the blank, answers are not summarized here.
The essays contain HTML code, to utilize this data the HTML code needs to be remove.
Essays sample:
+ The age feature
Age of the user.
Percentages of users by age brackets:
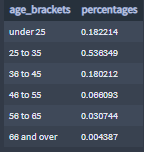
About 54% of the people that use OkCupid are between 25 and 35 years old.
print('Average age:')
print(profile_ages.mean())
Average age:
32.3402895939679+ The ethnicity feature
Percentages of users by ethnicity:










55% of the OkCupid user are 'white', 10% 'asian', 10% did not answer, 5% 'hispanic', 3.4% 'black' and 16.6% other and mixed races.
+ The sex feature
'm' - Male 'f' - Female
Percentages of users by sex:
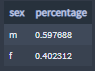
About 60% of the user identify them-self as male.
+ The orientation feature
Sexuality identification: 'straight' 'gay' 'bisexual'
Percentages of users by orientation:
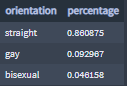
86% of the users identify as straight.
Percentages of users by sex and orientation:
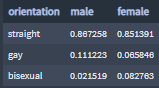
The majority of male and female OkCupid users identify them-self as 'straight'. But it is worth noticing:
the percentage of 'male' identifying them-self as 'gay' is roughly twice more than the percentage of 'female' identifying them-self as 'gay'.
the percentage of 'female' identifying them-self as 'bisexual' is four times more than the percentage of 'male' identifying them-self as 'bisexual'.
+ The pets feature
Percentages of users by pets:
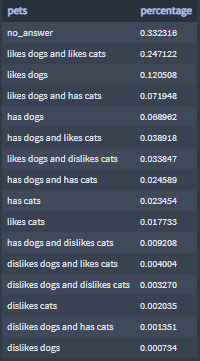
33% of the OkCupid users opted to not answers the pet question.
+ The income feature
An 'income' of -1, is a no answer.
Percentages of users by income:
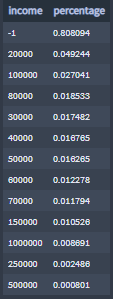
81% of the OkCupid users opted to not answer the income question.
▪ Formulating Questions
After investigating the OkCupid provided data, the features listed below emerged as been the most interesting to me:

I also define some of the features as categories:
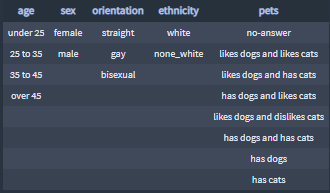
The questions:
What are the most significant words for each essay feature, for each essay feature by category and by multiple categories?
Before I can answer the questions using machine learning models, the essays' texts need to be pre-processed.
▪ Text Pre-processing
Before a text can be processed by a NLP model, the text data needs to be preprocessed. Text data preprocessing is the process of cleaning and prepping the text data to be processed by NLP models. Cleaning and prepping tasks:
Noise removal is a text pre-processing step concerned with removing unnecessary formatting from our text.
Tokenization is a text pre-processing step devoted to breaking up text into smaller units (usually words or discrete terms).
Normalization is the name we give most other text preprocessing tasks, including stemming, lemmatization, upper and lowercasing, and stopword removal.
Stemming is the normalization preprocessing task focused on removing word affixes.
Lemmatization is the normalization preprocessing task that more carefully brings words down to their root forms.
Tokenization:
In this project, I break down the essays into words on a sentence by sentence basis by using the sentence tokenizer nltk.tokenize.PunktSentenceTokenizer() class.
+ The features 'age and 'ethnicity'
To utilize the data of the features 'age' and 'ethnicity', I create two new categories with better functionality :
'age_bracket'
under_25,
25_to_35
36_to_45
over_45
'ethnicity_w'
white
none_white
+ The 'pet' feature
I replace the 'NaN' values with the value 'no_answer'.
+ Removing HTML code
The essay features string contain HTML code, to utilize this data the HTML code needs to be remove. See OkCupid DI for code.
Example before and after the HTML code removal (Profile-9 essay0):
essay0_profile9
"my names jake.<br />\ni'm a creative guy and i look for the same in others.<br />\n<br />\ni'm easy going, practical and i don't have many hang ups. i\nappreciate life and try to live it to the fullest. i'm sober and\nhave been for the past few years.<br />\n<br />\ni love music and i play guitar. i like tons of different bands. i'm\nan artist and i love to paint/draw etc. and i love creative\npeople.<br />\n<br />\ni've got to say i'm not too big on internet dating. you cant really\nget an earnest impression of anyone from a few polished paragraphs.\nbut we'll see, you never know."
essay0_text_profile9
"my names jake. i'm a creative guy and i look for the same in others. i'm easy going, practical and i don't have many hang ups. i appreciate life and try to live it to the fullest. i'm sober and have been for the past few years. i love music and i play guitar. i like tons of different bands. i'm an artist and i love to paint/draw etc. and i love creative people. i've got to say i'm not too big on internet dating. you cant really get an earn+ Sentence tokenization
Using the 'nltk.tokenize.PunktSentenceTokenizer()', I tokenize the essay texts into sentences.
Sample Profile-9 essay0:
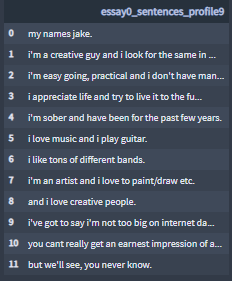
Note, the essay texts need further noise removal, before they can be utilized by a NLP model.
Example: punctuation, '.'.
+ Sentence word tokenization
I removed the remaining noise
I tokenize the sentences into words
I stem the word list by removing the stop-words
I lemmatize the words using Part-of-Speech Tagging
Note the word 'us': The result of preprocessing the word 'us' through lemmatizing with the part-of-speech tagging method nlt.corpus.reader.wordnet.synsets() and in conjunction with stop-words removal and the nltk.stem.WordNetLemmatizer().lemmatize() method, is that the word 'us' becomes 'u'.
This happens because the lemmatize (get_part_of_speech(word)) method removes the character 's' at the end of words tagged as nouns. The word 'us', which is not part of the stop-words list, is tagged as a noun causing the lemmatization result of 'us' to be 'u'.
Sample Profile-9 essay0:
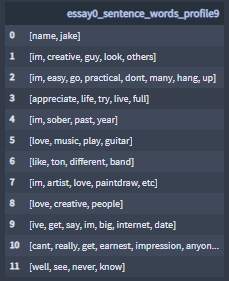
+ Pre-processes sentences
I create lists of pre-processed sentences by essays and by profile.
Sample Profile-9 essay0:
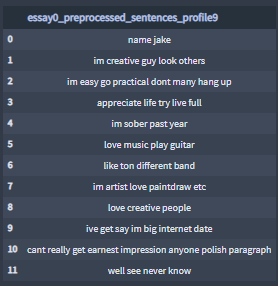
+ Pre-processed essays
I create lists of pre-processed essays by profile.
'name jake im creative guy look others im easy go practical dont many hang up appreciate life try live full im sober past year love music play guitar like ton different band im artist love paintdraw etc love creative people ive get say im big internet date cant really get earnest impression anyone polish paragraph well see never know'+ Pre-processes words
I create lists of pre-processed words by essay features and by profile.
Sample Profile-9 essay0:
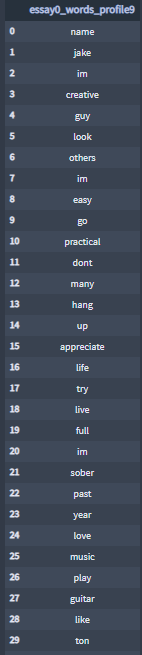
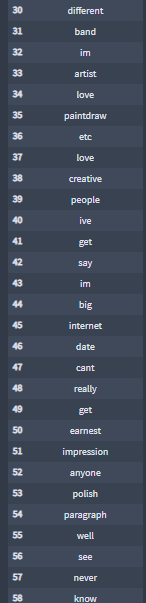
+ Storing the profiles DataFrame with the new columns
For this project, I use the the pandas.HDFStore class to store my DataFrames.
HDF5 is a format designed to store large numerical arrays of homogenous type. It came particularly handy when you need to organize your data models in a hierarchical fashion and you also need a fast way to retrieve the data. Pandas implements a quick and intuitive interface for this format and in this post will shortly introduce how it works. - The Glowing Python
# Creates a hdf5 file and opens in append mode
profiles_nlp = pd.HDFStore('data/profiles_nlp.h5')
# Stores (put, write) the data frame into store.h5 file
profiles_nlp['profiles'] = profiles+ Features and categories combinations
I save the essay features by categories.
The feature:

The categories:
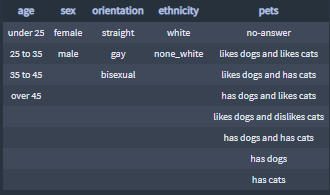
+ The features_cat() function:
From the 'profiles' DataFrame, the function stores the profiles essay features' words, sentence words, pre-processed sentences and pre-processed essays by essay feature and by entered category values.
The function:
Takes the arguments:
essay_name, list data type, defaulted to 'essay_name'
cat_names, list data type, defaulted to an empty list
cat-vals1, list data type, defaulted to an empty list
cat-vals2, list data type, defaulted to an empty list
df, DtaFrame data type, defualted to 'profiles'
Isolates the profiles essay features' words, sentence words, pre-processed sentences and pre-processed essays by essay feature and by entered categories values.
Stores the results.
Note: If no argument is entered, the function will save the profiles essay features words, pre-processed sentences and pre-processed essays by essay feature. The list 'cat_name' can not hold more than two values.
See OkCupid DI code for code.
- All the categories
Lists of all the profiles words, sentences words, and pre-processed sentences by essay features.
File example:
- The 'age_bracket' feature
Lists of all the profiles words, sentences words, pre-processed sentences and pre-processed essays by essay features and by age bracket.
File example:

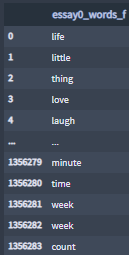
Sample essay0 words age under 25:

- The 'sex' category
Lists of all the profiles words, sentences words, pre-processed sentences and pre-processed essays by essay features and by sex.
File example:

Sample essay0 words female:
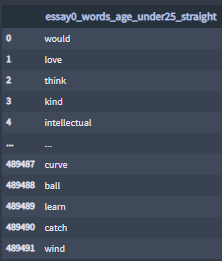
- The 'age_bracket' and 'orientation ' categories
Lists of all the profiles words, sentences words, pre-processed sentences and pre-processed essays by essay features, by sex and by age bracket.
File example:

Sample essay0 words age under 25 straight:
- Other categories:
- The 'sex' and 'age_bracket' categories
- The 'orientation' category
- The 'sex' and 'orientation' categories
- The 'ethnicity_w' category
- The 'pets' category
- The 'sex' and 'pets' categories
Please see OkCupid DI for the above categories results.
OkCupid TF-IDF
Term Frequency–Inverse Document Frequency (TF-IDF )
TF-IDF is a numerical statistic used to indicate how important a word is to each document in a collection of documents.
TF-IDF consists of two components, Term Frequency and Inverse Document Frequency.
Term Frequency is how often a term appears in a document.
TF = (Number of time the term occurs in the text) / (Total number of terms in text)
Inverse Document Frequency is a measure of how often a term appears across all documents of a corpus.
IDF = (Total number of documents / Number of documents with term t in it)
TF-IDF is calculated as the Term Frequency multiplied by the Inverse Document Frequency, the calculated TF-IDF is also referred as a TF-IDF score.
TF-IDF = TF * IDF
In this section I answer the question: What are the most significant words for each essay feature, for each essay feature by category and by multiple categories?
▪ Text Pre-processing
The essays are tokenize by terms and sentences, by essay features and categories. The essays text pre-processing was completed in the OkCupid DI section.
+ Loading the pre-processed data
For this project, I use the the pandas.HDFStore class to store my DataFrames.
▪ TF-IDF Scores Computation
TF-IDF is calculated as the Term Frequency multiplied by the Inverse Document Frequency, the calculated TF-IDF is also referred as a TF-IDF score.
TF-IDF = TF * IDF
+ The Tfidf class:
The class computes, for each essay feature entered category(es), the n highest terms TF-IDF score, and sums the scores by terms.
Class initialization:
Takes the attributes:
cat1, list data type, defaulted to [], essay category elements list
cat2, list data type, defaulted to [], essay category elements list
n, integer data type, defaulted to '15', (n highest terms TF-IDF score)
Additional attributes:
tfidf_scores, list of TF-IDF scores DataFrames, defaulted to []
tfidf_terms, list of TF-IDF terms DataFrames, defaulted to []
Class methods:
save_scores()
save_terms()
display_scores_dfs()
display_terms_dfs()
Private methods:
__tfidf_compute()
See OkCupid TF-IDF for code.
- Essay feature categories:
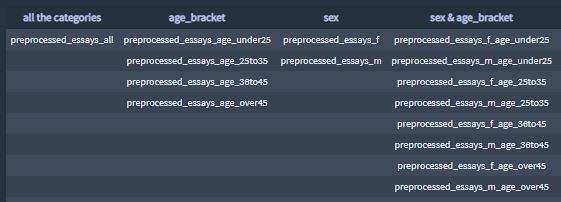
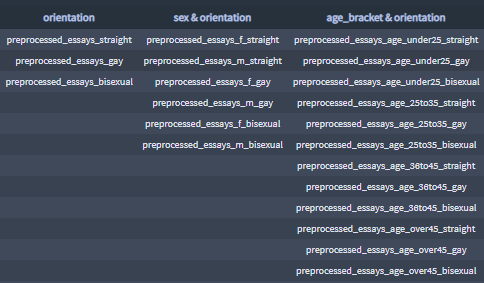
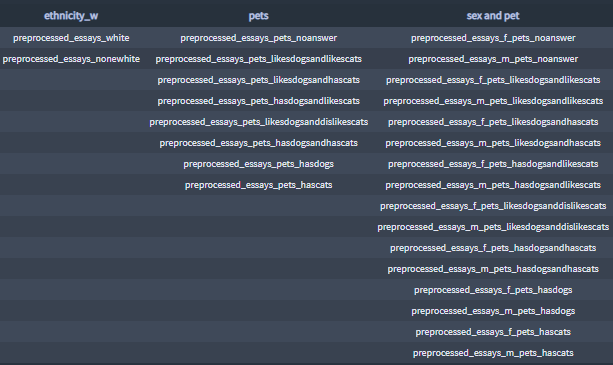
+ Most significant terms all categories
The TF-IDF documents are the all pre-processed profile essays by essay feature.
Highest 15, TF-IDF scores:
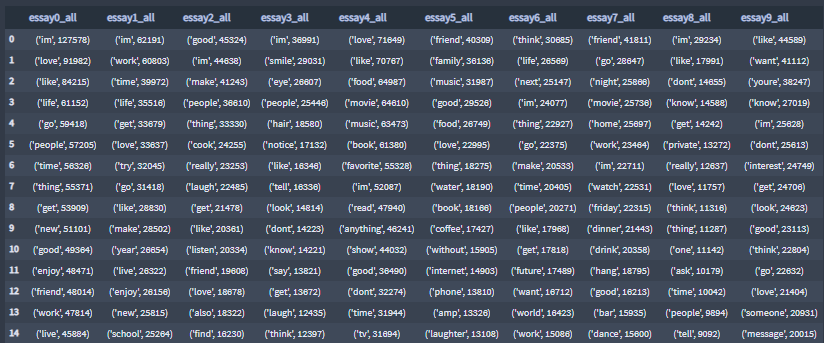
Highest 15, TF-IDF scores, terms:

- Other categories:
- age_bracket
- sex
- sex & age_bracket
- orientation
- sex & orientation
- age_bracket & orientation
- ethnicity_w
- pets
- sex & pets
Please see OkCupid TF-IDF for the above categories results.
▪ TF-IDF Terms Results Analysis
In this section, I analyze the similarity between sets of two TF-IDF terms results lists.
+ The Similarity class:
The class computes the similarity percentage between two essay terms lists of a Tfidf class instance.
For example:
From the Tfidf instance essays_ages, the class will compare the feature essay0 for the categories age_under_25 and age_25to35. note : the terms haven been sorted by TF-IDF scores, and the terms with a index 0 have the highest TF-IDF score.
The following is the computing similarity percentage equation that I formulated:

Class initialization:
Takes the attribute:
tfidf_instance, Tfidf instance class object
tfidf_instance_name, string data type
Additional attributes:
tfidf_terms, list of TF-IDF terms DataFrames, defaulted to tfidf_instance.tfidf_terms
n, integer data type, number of terms to compare, defaulted to tfidf_instance.n
sim_results, pandas DataFrame data type, similarity percentage results
tfidf_instance_name, string data type, name of the tfidf instance
Class methods:
display_results()
display_highest_sim()
display_lowest_sim(self)
save_results()
save_display_highest_sim()
save_display_lowest_sim()
Private methods:
__similarity_compute()
See OkCupid TF-IDF for code.
+ Similarities in the 'sex' category
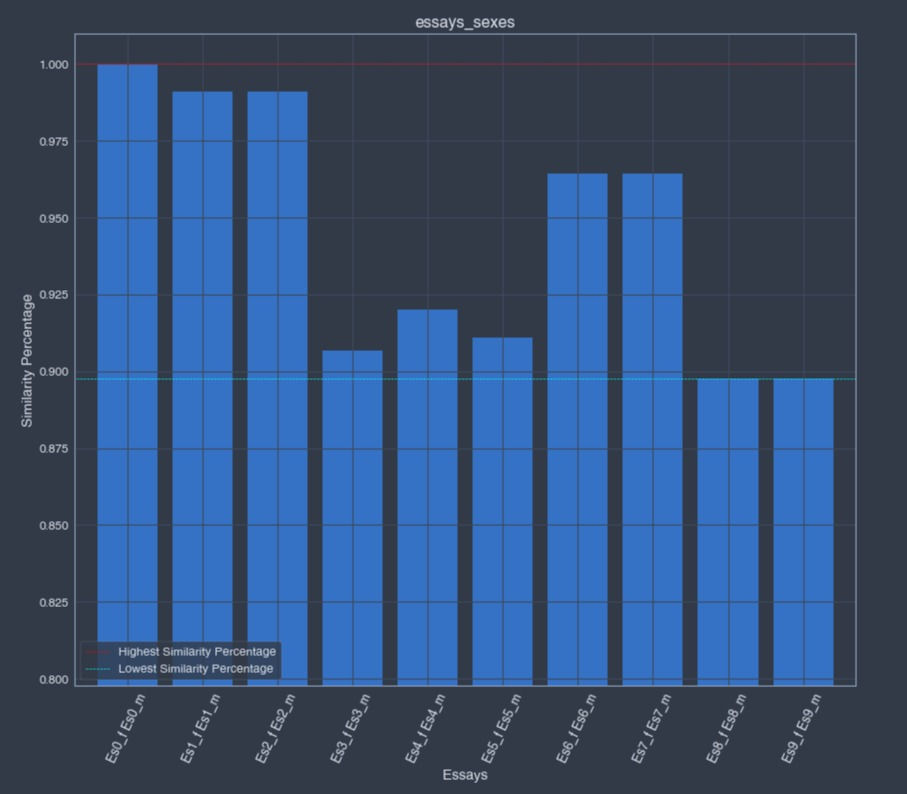
Similarity percentages between set of two essay TF-IDF terms lists from the Tfidf instance essays_sexes.
Similarity percentages:
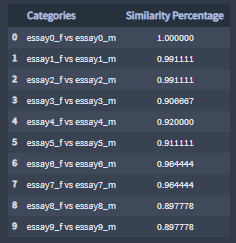
Highest similarity percentages:

Highest similarity percentages lists of terms:
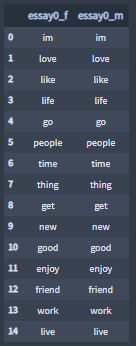
Lowest similarity percentages:
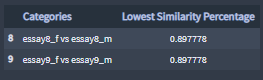
Lowest similarity percentages lists of terms:

Graph:
- Other categories:
- age_bracket
- sex & age_bracket
- orientation
- sex & orientation
- ethnicity_w
- pets
- sex & pets
Please see OkCupid TF-IDF for the above categories results.
+ The Similarity_all class
Similar to the class Tfidf, the class computes the similarity percentage between the TF-IDF all categories essays terms lists and another Tfidf class instance TF-IDF essays terms lists.
In other words, the class computes the similarity percentage between two essay TF-IDF terms lists based on the lists' essay features (ex:essay0), the category all vs another category (ex:age_bracker), the category's subcategories (ex:under25 ), and the lists' term indexes.
For the similarity percentage formula, see Tfidf section.
Class initialization:
Takes the attribute:
tfidf_instance, Tfidf instance class object
tfidf_instance_name, string data type
Additional attributes:
df_essays_all, DataFrame of all combines categories TF-IDf terms results
tfidf_terms, list of TF-IDF terms DataFrames, defaulted to tfidf_instance.tfidf_terms
n, integer data type, number of terms to compare, defaulted to tfidf_instance.n
sim_results, pandas DataFrame data type, similarity percentage results
tfidf_instance_name, string data type, name of the tfidf instance
col_essays_all, list data type, df_essays_all column names
Class methods:
display_results()
display_highest_sim()
display_lowest_sim(self)
save_results()
save_display_highest_sim()
save_display_lowest_sim()
graph()
Private methods:
__similarity_compute()
See OkCupid TF-IDF for code.
+ Similarities between the 'all' and 'sex' categories
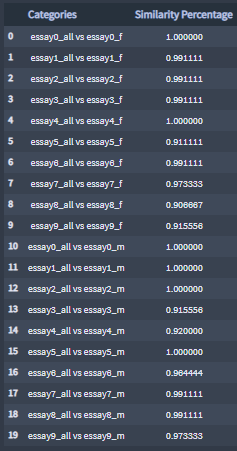
Similarity percentages between set of two essay TF-IDF terms lists from the Tfidf instance essays_all and essays_sexes.
Similarity percentages:
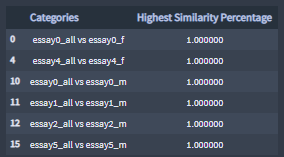
Highest similarity percentages:
Highest similarity percentages lists of terms:
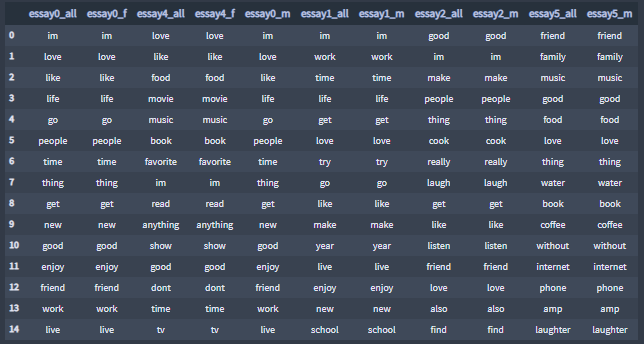
Lowest similarity percentages:

Lowest similarity percentages lists of terms:

Graph:
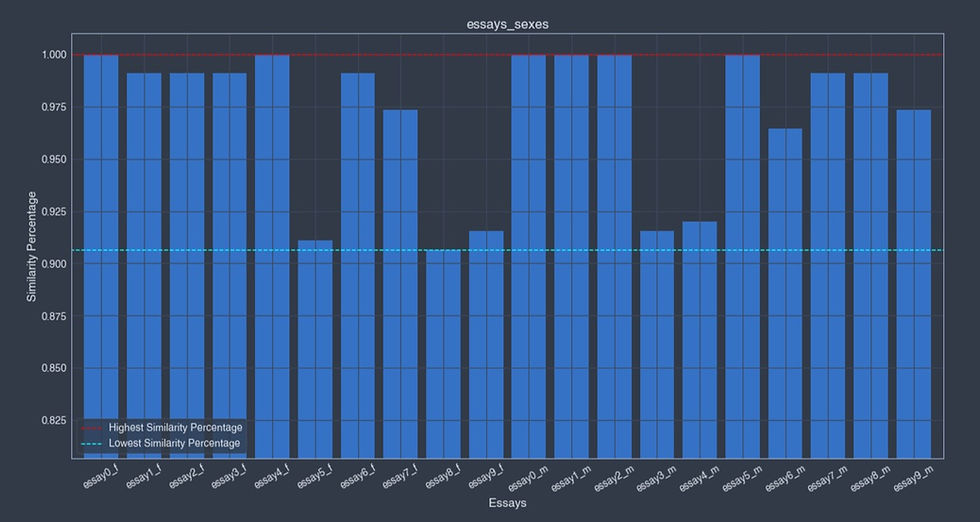
- Other categories:
- age_bracket
- sex & age_bracket
- orientation
- sex & orientation
- ethnicity_w
- pets
- sex & pets
Please see OkCupid TF-IDF for the above categories results.



Comments