
Read the News Analysis
- Alex Ricciardi

- Dec 5, 2020
- 4 min read
Updated: Dec 15, 2020
A Codecademy practice project from the Data Science Path Natural Languages Processing (NLP) course, Term Frequency-Inverse Document Frequency Section.
▪ Overview
Newspapers and their online formats supply the public with the information we need to understand the events occurring in the world around us. From politics to sports, the news keeps us informed, in the loop, and ready to make decisions about how to act in a rapidly changing world.
Given the vast amount of news articles in circulation, identifying and organizing articles by topic is a useful activity. This can help you sift through the enormous amount of information out there so you can find the news relevant to your interests, or even allow you to build a news recommendation engine!
The News International is the largest English language newspaper in Pakistan, covering local and international news across a variety of sectors. A selection of articles from a Kaggle Dataset of The News International articles is provided in the workspace.
In this project I used term frequency-inverse document frequency (tf-idf) to analyze each article’s content and uncover the terms that best describe each article, providing quick insight into each article’s topic.
▪ Project Goal:
Analyze news documents using TF-IDF MLP supervised machine learning models.
▪ Project Requirements
Be familiar with:
Python3
NLP (Natural Languages Processing)
The Python Libraries:
Pandas
NLKT
Sklearn
▪ Links:
Text Pre-processing
Before a text can be processed by a NLP model, the text data needs to be pre-processed.
Text data pre-processing is the process of cleaning and prepping the text data to be processed by NLP models.
Cleaning and prepping tasks:
Noise removal is a text pre-processing step concerned with removing unnecessary formatting from our text.
Tokenization is a text pre-processing step devoted to breaking up text into smaller units (usually words or discrete terms).
Normalization is the name we give most other text preprocessing tasks, including stemming, lemmatization, upper and lowercasing, and stopword removal.
- Stemming is the normalization preprocessing task focused on removing word
affixes.
- Lemmatization is the normalization preprocessing task that more carefully brings
words down to their root forms.
To improve the performance of lemmatization, each word in the processed text is assigned parts of speech tag, such as noun, verb, adjective, etc. The process is call Part-of-Speech Tagging.
▪ Pre-processed Project Article Sample:
Article-6:
'SYDNEY: Cricket fever has gripped Australia with the World Cup just days away. Fans from around the world have thronged to the country and hotels are capitalising. Prices of rooms have almost doubled to 300 dollars and hotels are experiencing full bookings. Experts estimate that during the mega event Australia will generate 1.5 million US dollars just from hotel bookings. If the cost of internal air travel, taxis and tickets is taken into consideration, Australia stands to generate two million US dollars during the World Cup.'Pre-processed Aricle-6:
sydney cricket fever have grip australia with the world cup just day away fan from around the world have throng to the country and hotel be capitalise price of room have almost double to dollar and hotel be experience full book expert estimate that during the mega event australia will generate million u dollar just from hotel book if the cost of internal air travel taxi and ticket be take into consideration australia stand to generate two million u dollar during the world cupTF-IDF
Term Frequency-Inverse Document Frequency, TF-IDF, is a numerical statistic used to indicate how important a word is to a document (text data, corpus).
tf-idf consists of two components, term frequency and inverse document frequency term frequency is how often a word appears in a document. This is the same as bag-of-words’ word count
inverse document frequency is a measure of how often a word appears across all documents of a corpus
tf-idf is calculated as the term frequency multiplied by the inverse document frequency, the calculated tf-idf is also referred as a tf-idf score.
▪ Tfi-df score:
Tf-idf scores are calculated on a term-document basis. That means there is a tf-idf score for each word, for each document. The tf-idf score for some term t in a document d in some corpus is calculated as follows: tfidf(t,d) = tf(t,d) * idf(t,corpus)
tf(t,d) is the term frequency of term t in document d
idf(t,corpus) is the inverse document frequency of a term t across corpus
Note: the Term Frequency element is also referred as the Bag-of-Words model results.
▪ BoW:
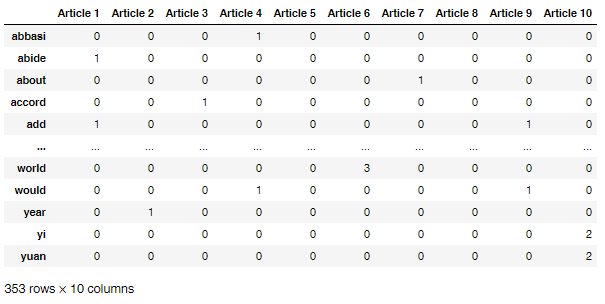
Bag-of-Words (BoW), also referred to as the unigram model, is a statistical language model based on word count.
BoW can be implemented as a Python dictionary with each key set to a word and each value set to the number of times that word appears in a text.
For BoW, training data is the text that is used to build a BoW model.
BoW test data is the new text that is converted to a BoW vector using a trained features dictionary.
A feature vector is a numeric depiction of an item’s salient features.
Feature extraction (or vectorization) is the process of turning text into a BoW vector.
A features dictionary is a mapping of each unique word in the training data to a unique index. This is used to build out BoW vectors.
BoW has less data sparsity than other statistical models. It also suffers less from overfitting.
BoW has higher perplexity than other models, making it less ideal for language prediction.
One solution to overfitting is language smoothing, in which a bit of probability is taken from known words and allotted to unknown words
▪ Articles BoW results DataFrame overview:
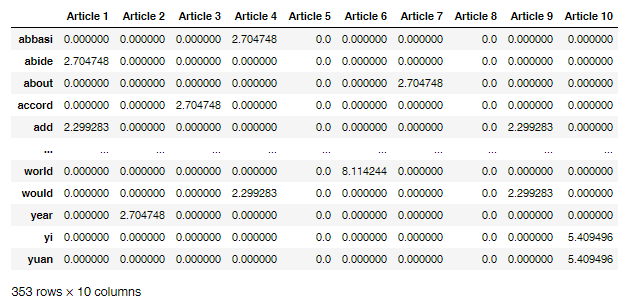
▪ Articles tf-idf scores results DataFrame overview:
Results Analysis
To analyze the results, I use the process of labeling each article's highest-scoring tf-idf term to determined each article's topic.
While the process of labeling the highest-scoring tf-idf term is a more naïve approach than others, it is a quick and easy way of getting insight into the topic.
▪ Articles Topics DataFrame:

By using NLP supervised machine learning models we can gain insight into news articles topics without having the need to read them.
For example, we can determine, with good certainty, that the article-6's topic is linked to Australia.
To access the project's python code, click on the link below:



Comments